We recently announced the release of StarRocks 2.2 with a bunch of new features and enhancements, including resource isolation, Java UDFs, support for JSON data types, external table support for Apache Hudi, data lake analytics optimization, and partial updates using the primary key model.
You are welcome to trial these new features and give feedback on any issues you may find.
Resource Isolation
Resource isolation is one of the most eagerly awaited features of StarRocks users. StarRocks 2.2 introduces resource groups to implement resource isolation. Users can configure resource groups to isolate CPU and memory resources. This way, the workloads of different tenants can use dedicated resources and run in the same cluster without affecting each other, which significantly improves resource utilization. Test results show that the response time to small queries is shortened by 2-4 times after resource groups are applied. In some scenarios, the performance of resource groups is comparable to that of physical isolation.
In addition, StarRocks' pipeline engine enables elastic scheduling of resource groups. When the cluster is idle, queries can make full use of resources. When the cluster load increases, resources in resource groups can be scaled accordingly. This achieves better resource utilization than physical isolation.
Java UDFs
Despite the rich functions provided by StarRocks, users still need to use other special processing logic, especially for extract, transform, load (ETL) tasks. StarRocks 2.2 supports Java UDFs. Scalar functions, aggregate functions, window functions, and table functions can be implemented by using custom functions. This allows users to customize and extend functions on StarRocks, for example, implementing Hadoop UDFs on StarRocks. For more information, see Java UDFs.
Support for JSON Data Types
Data to be analyzed may come in various formats, such as structured data, server logs, IoT data, and app measurement data. As business scenarios become more diversified and complex, "static schema" may be insufficient to handle this complexity and sometimes becomes even troublesome. In scenarios that have frequent column additions and deletions, nested data structures, sparse data, and unknown column types, developers may need to perform frequent and tedious maintenance operations. In addition, data importing from other systems may become more complex.
JSON data is semi-structured data. Its simple design and flexibility make it easy to read and process. If data is stored and processed as JSON, upstream users can add or delete key-value pairs as needed, data analysts can query JSON data anytime they want, and developers no longer need to make schema changes. StarRocks 2.2 introduces the following first-phase JSON features:
-
Supports JSON data types.
-
Uses binary data to replace JSON strings, improving query performance by 1x.
-
Provides rich JSON functions, including JSON_EACH. For more information, see JSON functions.
External Table Support for Apache Hudi
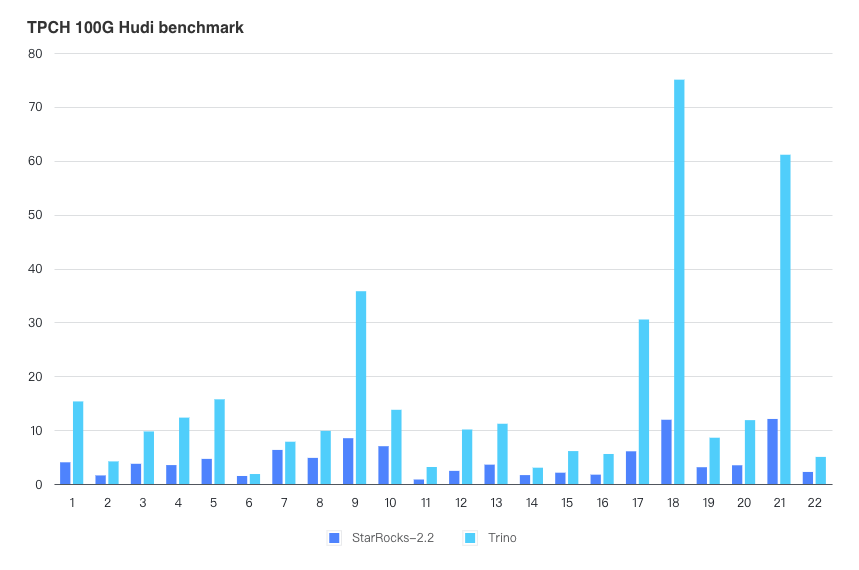
External table support for Apache Hudi is contributed by the Alibaba Cloud open source big data team. This feature further enhances the data lake analytics capabilities of StarRocks, enables efficient queries on Copy-on-Write (CoW) tables, supports file types such as Parquet and ORC as well as storage systems including HDFS, AWS S3, and Alibaba Cloud OSS.
During TPC-H 100 GB tests that are performed on the same machines, StarRocks 2.2 delivers a performance 3.69x of Trino 358. The following figure shows the test results.
Data Lake Analytics Optimization
More and more users still choose to build data lakes on top of object storage. To accommodate this need, we optimized the performance of using Apache Hive external tables to query data in object storage systems, such as AWS S3 and Alibaba Cloud OSS. After the optimization, the performance is comparable to that of querying data from HDFS. Additionally, late materialization of ORC files is supported, reducing query I/Os and accelerating queries on a large number of small files.
In terms of metadata management, StarRocks automatically updates metadata by periodically consuming Hive metastore events (such as data changes and partition changes). Users no longer need to manually refresh or re-create a Hive table each time partition data changes or columns are added.
In addition, StarRocks can query DECIMAL and ARRAY data from Apache Hive.
Partial Updates Using Primary Key Model
The Primary Key model supports partial updates in StarRocks 2.2. Users can run Stream Load, Broker Load, and Routine Load tasks to update only part of the columns in a flat table in real time. In scenarios such as real-time order updates and multi-stream real-time JOIN, partial updates simply the processing of real-time update tasks. Users do not need to maintain additional windows or read data that is not updated.
Different from the "REPLACE_IF_NOT_NULL" aggregation method that is used in the aggregation model, partial update in StarRocks eliminates the need for sort-merge joins, which significantly improves the query performance. The partial update feature in StarRocks 2.2 does not apply to tables that have more than 100 columns. In addition, this feature requires SSDs for higher random I/O.
***
During StarRocks 2.2 development, 57 contributors from the StarRocks community submitted a total of 817 commits. We really appreciate the excellent work they have done.
@mofeiatwork @Linkerist @meegoo @trueeyu @dirtysalt @sevev @Youngwb @Astralidea @kangkaisen @liuyehcf @stdpain @xiaoyong-z @chaoyli @decster @HangyuanLiu @Seaven @stephen-shelby @gengjun-git @ZiheLiu @silverbullet233 @Pslydhh @mchades @ABingHuang @satanson @wangruin @rickif @wyb @miomiocat @laotan332 @adzfolc @DorianZheng @wuleistarrocks @johndinh391 @caneGuy @sduzh @karan-kap00r @wanpengfei-git @creatstar @xlwh @Gabriel39 @Ielihs @DeepThinker666 @hffariel @SaintBacchus @bigdata-kuxingseng @blackstar-baba @staman96 @Johnsonginati @zbtzbtzbt @Gri-ffin @jsinwell @aaawuanjun @DebayanSen96 @RishiKumarRay @Ccuurryy @wuqiao @screnwei
