Introduction
StarRocks query cache, what is it?
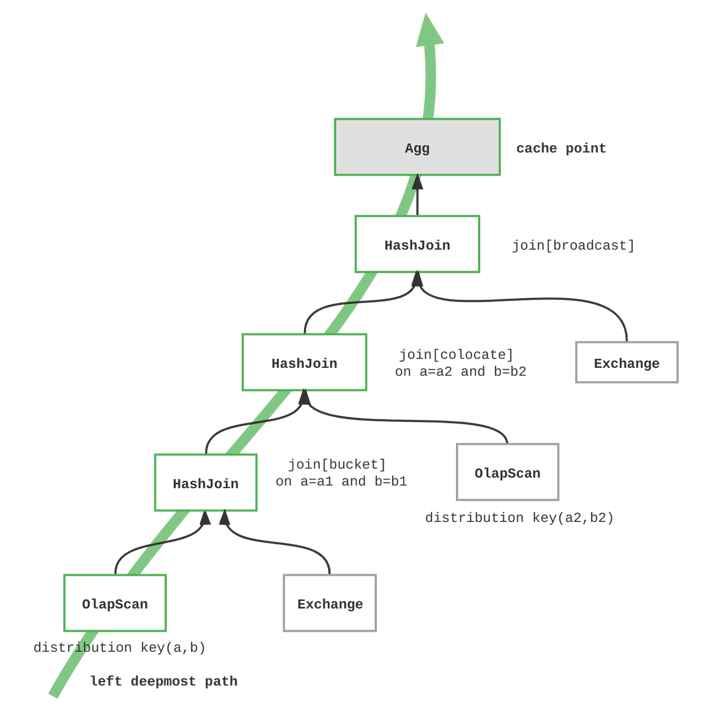
Engineered for maximum cache-hits rate
-
Semantically equivalent queries
-
Queries with overlapping scanned partitions: Predicate-based query splitting
-
Append-only data changes (no update or delete): Multi-version caching
Semantic equivalence
These two queries make effective use of the query cache because the subquery of the first example is semantically equivalent (or identical) to the second, so the results are reused and pulled from the cache.
SELECT
(ifnull(sum(murmur_hash3_32(hour)), 0)
+ ifnull(sum(murmur_hash3_32(k0)), 0)
+ ifnull( sum( murmur_hash3_32(__c_0)), 0)
) AS fingerprint
FROM
( SELECT date_trunc( hour', ts) AS hour,
ko,
sum(v1). AS __с_0
FROM
tO
WHERE
ts
BETWEEN '2022-01-03 00:00:00' and '2022-01-03 23:59:59'
GROUP BY
date_trunc("hour', ts),
k0
) AS t;
and
SELECT date_trunc('hour', ts) AS hour,
k0,
sum(v1) AS __c_0
FROM t0
WHERE ts
BETWEEN '2022-01-03 00:00:00' AND '2022-01-03 23:59:59'
GROUP BY date_trunc('hour', ts),
k0;
Overlap in partition: Predicate-based query splitting
SELECT date_trunc( 'day', ts) as day,
sum (v0)
FROM t0
WHERE ts
BETWEEN '2022-01-02 12:30:00' AND '2022-01-14 23:59:59'
GROUP BY day;
and
SELECT date_trunc( 'day', ts) as day,
sum(v0)
FROM t0
WHERE ts >= '2022-01-02 12:30:00'
AND ts < '2022-01-05 00:00:00'
GROUP BY day;
Append-only data loading: Multi-version caching
Combining with the query result cache
-
Aggregation queries are frequently executed
-
Queries are similar but not necessarily identical
-
Data is volatile, as long as the changes are append-only
-
Queries are non-aggregated
-
Queries are repeated and identical
-
Data has very low volatility
How to use it
Preparation
SET enable_query_cache=true;
An example
SELECT date_trunc( 'day', ts) as day,
sum(v0 )
FROM t0
WHERE ts >= '2022-01-02 12:30:00'
AND ts < '2022-01-05 00:00:00'
GROUP BY day;
CREATE TABLE `lineorder_flat` (
`lo_orderdate` date NOT NULL COMMENT "",
`lo_orderkey` int(11) NOT NULL COMMENT "",
`lo_orderpriority` varchar(100) NOT NULL COMMENT "",
`lo_shippriority` tinyint(4) NOT NULL COMMENT "",
`lo_quantity` tinyint(4) NOT NULL COMMENT "",
`lo_extendedprice` int(11) NOT NULL COMMENT "",
`lo_ordtotalprice` int(11) NOT NULL COMMENT "",
`lo_discount` tinyint(4) NOT NULL COMMENT "",
`lo_revenue` int(11) NOT NULL COMMENT "",
`lo_supplycost` int(11) NOT NULL COMMENT "",
`lo_tax` tinyint(4) NOT NULL COMMENT "",
`lo_commitdate` date NOT NULL COMMENT "",
`lo_shipmode` varchar(100) NOT NULL COMMENT "",
`s_nation` varchar(100) NOT NULL COMMENT "",
`s_region` varchar(100) NOT NULL COMMENT "",
`p_category` varchar(100) NOT NULL COMMENT "",
`p_brand` varchar(100) NOT NULL COMMENT ""
) ENGINE=OLAP
DUPLICATE KEY(`lo_orderdate`, `lo_orderkey`)
COMMENT "olap"
PARTITION BY RANGE(`lo_orderdate`)
(PARTITION p1 VALUES [("0000-01-01"), ("1993-01-01")),
PARTITION p2 VALUES [("1993-01-01"), ("1994-01-01")),
PARTITION p3 VALUES [("1994-01-01"), ("1995-01-01")),
PARTITION p4 VALUES [("1995-01-01"), ("1996-01-01")),
PARTITION p5 VALUES [("1996-01-01"), ("1997-01-01")),
PARTITION p6 VALUES [("1997-01-01"), ("1998-01-01")),
PARTITION p7 VALUES [("1998-01-01"), ("1999-01-01")))
DISTRIBUTED BY HASH(`lo_orderkey`) BUCKETS 48
PROPERTIES (
"replication_num" = "1",
"colocate_with" = "groupxx1",
"in_memory" = "false",
"storage_format" = "DEFAULT",
"enable_persistent_index" = "false",
"replicated_storage" = "false",
"compression" = "LZ4"
);
Typical Scenarios
-
Aggregated queries on flat table data models.
-
Aggregated JOIN queries on star-schema data models.
The query cache can greatly help in cases where we need to speed up queries that have the same or similar structure and are executed frequently and concurrently. For example, in the code blocks below you will find that queries Q1, Q2, Q3, and Q4 all have the same pattern and can benefit from the query cache (the range for the filter on l0_orderdate changes, but the rest of the query is the same across Q1 - Q4).
-- Q1 : lo_orderdate ranges ['1993-01-01', '1993-12-31']
SELECT sum(lo_revenue), year(lo_orderdate) AS year, p_brand
FROM lineorder_flat
WHERE p_category = 'MFGR#12' AND
s_region = 'AMERICA' AND
lo_orderdate between '1993-01-01' and '1993-12-31'
GROUP BY year, p_brand
Q1 : lo_orderdate ranges ['1993-01-01', '1993-12-31']
-- Q2: widen the time range, o_orderdate ranges ['1993-01-01', '1994-12-31']
SELECT sum(lo_revenue), year(lo_orderdate) AS year, p_brand
FROM lineorder_flat
WHERE p_category = 'MFGR#12' AND
s_region = 'AMERICA' AND
lo_orderdate between '1993-01-01' and '1994-12-31'
GROUP BY year, p_brand
Q2: widen the time range, o_orderdate ranges ['1993-01-01', '1994-12-31']
-- Q3: narrow the time range, o_orderdate ranges ['1993-01-01', '1993-06-30']
SELECT sum(lo_revenue), year(lo_orderdate) AS year, p_brand
FROM lineorder_flat
WHERE p_category = 'MFGR#12' AND
s_region = 'AMERICA' AND
lo_orderdate between '1993-01-01' and '1993-06-30'
GROUP BY year, p_brand
Q3: narrow the time range, o_orderdate ranges ['1993-01-01', '1993-06-30']
-- Q4: slide time range, o_orderdate ranges ['1993-06-30', '1994-06-30']
SELECT sum(lo_revenue), year(lo_orderdate) AS year, p_brand
FROM lineorder_flat
WHERE p_category = 'MFGR#12' AND
s_region = 'AMERICA' AND
lo_orderdate between '1993-06-30' and '1994-06-30'
GROUP BY year, p_brand
Q4: slide time range, o_orderdate ranges ['1993-06-30', '1994-06-30']
-
For monitoring or dashboard platforms, the dataset is ingested incrementally as time goes by, and users are interested in the summary of the data in different periods
-
For web servers that generate dynamic pages based on database content
-
For user-facing analytics with high QPS involving summarization and grouping of data by certain dimensions or measures
Warming up the cache
Best practices
-
Select a single date/datetime column as the partition-by column. This column should reflect how the data is incrementally ingested over time and how the queries are filtered by time ranges. If you have multiple date/datetime type columns, choose the one that best matches these criteria.
-
Choose an appropriate partition size. The most recent data will update the latest partitions of the table, so the cache entries for those partitions are likely to be invalidated frequently. You want to avoid having too large or too small partitions that affect the cache hit rate.
-
Specify a bucket count in the range of several dozen in the data distribution description. This will ensure that each query can cover enough tablets on each BE to enable the query cache. If the bucket count is too low, the query cache will not work because it requires the tablet number on each BE to be greater than or equal to pipeline_dop.
Performance benchmark
no_cache/cache_hitin terms of query latency. The detailed performance test results are in the appendixNote that for all tests, the query cache is warmed up fully
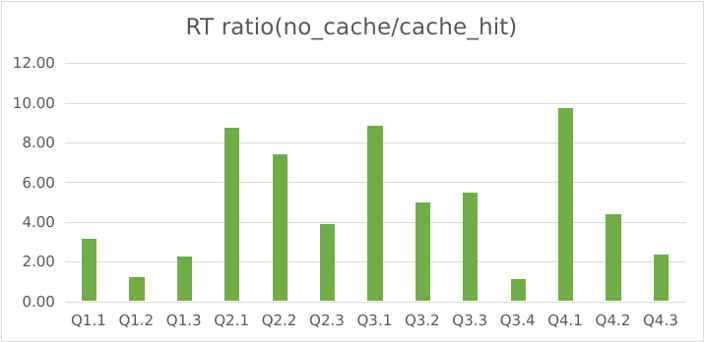
Flat table schema test
The test uses the SSB_flat dataset (link in references). The tests were run on three servers, each with 16 cores and 64GB memory. 10 concurrent clients were used. The ratio of query latency without the query cache to with the query cache was reported.
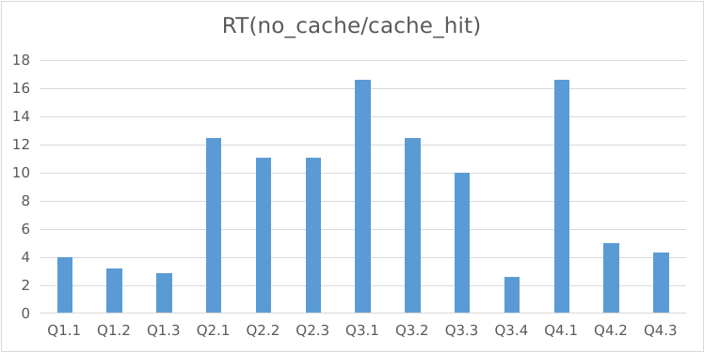
Star schema test
The test uses the SSB original multi-table dataset (link in references). The tests were run on three servers, each with 16 cores and 64GB memory. 10 concurrent clients were used. The ratio of query latency without the query cache to with the query cache was reported.
Query Cache on vs. Query Cache off
Conclusion
Reference
- StarRocks Benchmarks
- Query cache docs
- Pat O'Neil, Betty O'Neil, Xuedong Chen: Star Schema Benchmark.
- Star Schema flat benchmark in ClickHouse documentation.
