We recently announced the release of StarRocks 2.1 with a bunch of new features and improvements, including external table support for Apache Iceberg, pipeline execution engine, support for loading tables with up to 10,000 columns, performance optimization for first-time scan and page cache, and support for SQL fingerprinting.
External table support for Apache Iceberg (in public preview)
Apache Iceberg is one of the most popular solutions for building data lakes. StarRocks 2.1 extends external table support from Apache Hive™ to Apache Iceberg. This enables users to directly query data stored in an Apache Iceberg data lake without having to import data, accelerating data lake analytics.
TPC-H 100 GB testing results show that StarRocks delivers a query performance 3x to 5x that of Trino (Presto SQL), thanks to its innovative features such as cost-based optimizer (CBO), vectorized execution engine, and C++ native execution.
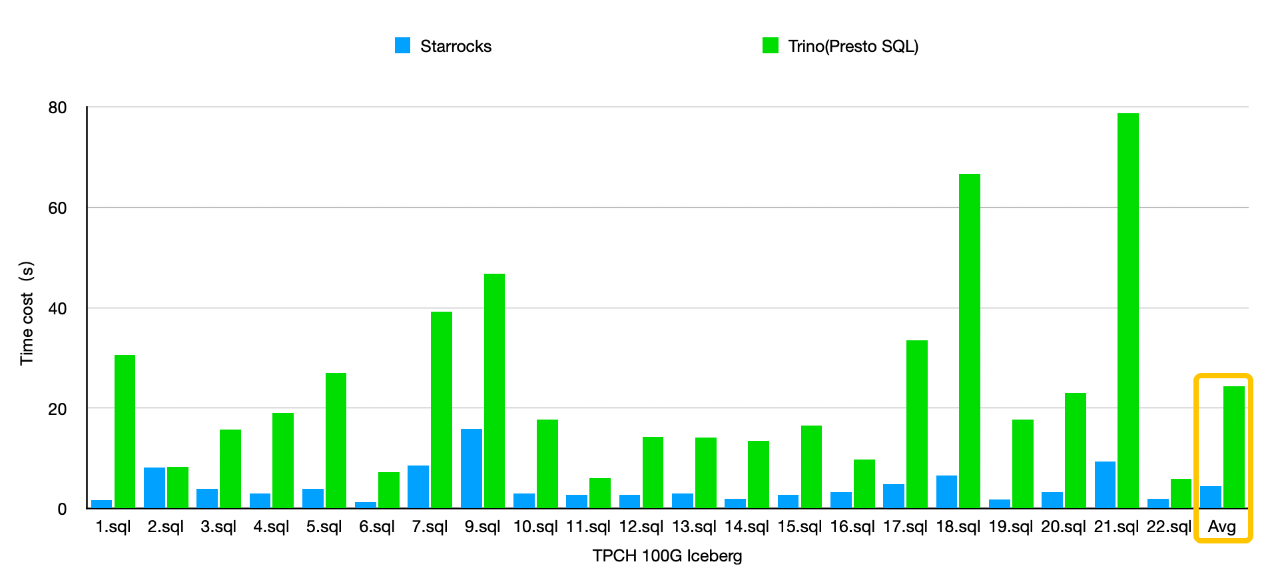
In the upcoming versions, we will further optimize Apache Iceberg query performance and extend support for more data lake solutions such as Apache Hudi.
Pipeline execution engine (in public preview)
Previous execution engines use thread scheduling to achieve multi-core scheduling, which has two prominent issues:
- In high-concurrency scenarios, data dependency and blocking of I/O operations will increase context switching, resulting in high scheduling costs.
- Complex queries always involve complex and tricky parallelism settings.
StarRocks' pipeline execution engine adopts a more efficient coroutine scheduling mechanism, in which data-dependent pipeline drivers are asynchronously executed, so are I/O operations. This mechanism reduces context switching overhead. In high-concurrency scenarios, the performance of some queries is 2x that provided by previous execution engines, and the CPU utilization is also significantly improved. We also see considerable performance improvement in SSB, TPC-H, and TPC-DS testing. Moreover, the query parallelism can be adaptively adjusted, eliminating the need for complex manual operations.
Support for loading tables with up to 10,000 columns
In traditional warehouse modeling, it is a common practice to create a denormalized wide table, for the purpose of easier use and better query performance. In scenarios such as user profiling, engineers usually create a wide table that has hundreds of columns, and in extreme cases, even thousands of columns. After data at such large scale (thousands of columns and hundreds of millions of rows) is imported, especially when there are large strings, row-based compaction will eat up a lot of memory, making the system prone to out-of-memory (OOM) and slowing down the compaction.
StarRocks 2.1 redesigns the way compaction is performed. In StarRocks 2.1, multiple versions of data can be merged by column in different batches. It also optimizes how large strings are processed, reducing memory consumption. When up to 10,000 columns of data is imported, memory usage is reduced by dozens of times, and compaction performance is improved by 2x.
Performance optimization for first-time scan and page cache
In big data analytics, some cold data needs to be read from the disk (first-time scan), while some hot data can be directly read from memory. The query performance of these two data read modes can differ by several or even dozens of times due to random I/O. StarRocks reduces random I/O by reducing the file count, indexing lazy load, and adjusting file structure. This improves first-time scan performance. The improvement is especially noticeable if a first-time scan happens on HDDs.
SSB 100 GB testing results show that some SQL queries that involve first-time scans (such as Q2.1, Q3.1, Q3.2) have a 2x to 3x query performance improvement.
StarRocks also optimizes its page cache policy. In some scenarios, StarRocks stores data in its original format, without the need for Bitshuffle encoding or decoding, which improves the cache hit rate and significantly improves query efficiency.
SQL fingerprinting
SQL fingerprint is an MD5 value calculated for SQLs of the same type. SQLs of the same type are "SQL texts that have only different constants after being normalized". By summarizing and analyzing SQL fingerprints and related information, engineers can easily know the SQL types, the frequency of their occurrence, the resources consumed, and the processing time of each SQL type. This helps quickly identify SQLs that consume a large portion of resources and take a long processing time, and enables efficient analysis and optimization.
SQL fingerprinting is mainly used for optimizing slow queries and improving system resource utilization (such as CPU, memory, disk read/write). For example, if you find that the CPU or memory usage of your cluster is not high, but the disk usage constantly approximates 100%, you can identify SQL fingerprints that have the highest proportion of disk reads, and then work out solutions to optimize related SQLs.
For more features and improvements in StarRocks 2.1, see StarRocks Documentation.
Apache®, Apache Hive™, Apache Hudi, Apache Iceberg, and their logos are either registered trademarks or trademarks of the Apache Software Foundation in the United States and/or other countries.
