StarRocks 3.4 expands into the AI ecosystem with ANN indexes, Python UDFs, and Arrow Flight support, enabling vector search and seamless extensibility. This version also enhances lakehouse integration, adding Apache Iceberg V2 equi-delete optimization, smarter statistics collection, improved data caching, and optimizations for large-scale file scanning. Additionally, improvements in table creation, data ingestion, and system stability make StarRocks 3.4 even more efficient and user-friendly.
This blog will dive into these new features and optimizations in detail.
Better Support for the AI Ecosystem
Vector Index
Approximate Nearest Neighbor (ANN) algorithms enable fast high-dimensional similarity search. These algorithms efficiently find the most similar vectors to a given vector with minimal sacrifice on recall. This capability is essential for recommender systems, search, RAG for LLMs, and more.
StarRocks 3.4 adds support for two ANN indexes:
-
IVFPQ (Inverted File Index with Product Quantization) – Efficient for large-scale datasets by reducing the search space while maintaining high accuracy.
-
HNSW (Hierarchical Navigable Small World) – Provides fast, high-quality nearest neighbor search with a graph-based structure.
To use vector index with StarRocks 3.4, set FE configuration set enable_experimental_vector=true.
Here is an example:
-- Create an IVFPQ vector index based on an ARRAY field
CREATE TABLE test_ivfpq (
id BIGINT(20),
vector ARRAY<FLOAT>,
INDEX ivfpq_vector (vector) USING VECTOR (
"index_type" = "ivfpq",
"dim"="5",
"metric_type" = "l2_distance",
"is_vector_normed" = "false",
"nbits" = "16",
"nlist" = "40"
)
);
-- Insert arrays.
INSERT INTO test_ivfpq VALUES (1, [1,2,3,4,5]), (2, [4,5,6,7,8]);
-- Perform a vector similarity search with SQL
SELECT *
FROM (SELECT id, approx_l2_distance([1,1,1,1,1], vector) score
FROM test_ivfpq) a
WHERE id in (1, 2, 3) AND score < 40
ORDER BY score
LIMIT 3;
Python UDF [Experimental]
While StarRocks already offers hundreds of built-in functions and supports Java UDFs, the Python ecosystem dominates data science and AI workflows. StarRocks 3.4 introduces Python UDF, making it easier for Python users to define custom functions.
With Python UDFs, users can preprocess training data, run embedded model inference, and leverage Python libraries directly within StarRocks. This feature provides greater flexibility and seamless integration with AI pipelines—all with simple Python code.
-- Create a Python UDF in inline mode to clean text
CREATE FUNCTION python_clear_text(STRING) RETURNS STRING
TYPE = 'Python'
SYMBOL = 'clear_text'
FILE = 'inline'
INPUT = 'scalar' -- Use 'arrow' for better performance on large datasets
AS
$$
import string
def clear_text(input_text):
translator = str.maketrans('', '', string.punctuation) # Remove punctuation
return input_text.translate(translator).lower() # Convert to lowercase
$$;
-- Use the Python UDF to clean text in a query
SELECT id, python_clear_text(str_field)
FROM tbl; -- 'tbl' contains columns: id, str_field
Arrow Flight [Experimental]
Arrow Flight in StarRocks 3.4 provides a faster and more efficient way to retrieve query results for users who frequently export large datasets. Compared to the traditional MySQL protocol, Arrow Flight enables higher-throughput data transfer, making it ideal for AI applications that require cross-system data collaboration across multiple sources.
Additionally, this feature helps reduce query load on StarRocks Frontend (FE), improving overall system stability and performance.
Data Lake Analytics
Optimized Iceberg V2 Equality Delete Read
StarRocks 3.3 introduced read support for Iceberg V2 equality delete. However, when frequent upserts/deletes occur, query scanning could repeatedly read the same delete files, leading to performance degradation and high memory usage.
StarRocks 3.4 optimizes this by introducing a dedicated Iceberg eq-delete scan node in the query plan. Using shuffle or broadcast strategies, it eliminates redundant reads, delivering multi-fold performance gains in delete-heavy workloads.
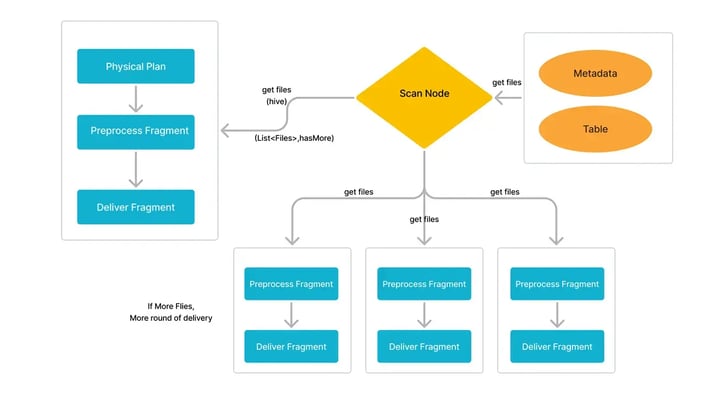
Async Scan Framework
Fetching the file list can be a significant bottleneck for large-scale data lake queries, often delaying query execution. In StarRocks 3.4, the new async scan framework enables parallel execution, allowing the Back End (BE) to start query execution while the Front End (FE) continues fetching file lists.
This significantly reduces query latency, especially for cold queries where file lists aren’t cached. Additionally, users can reduce the size of the file list cache without sacrificing performance, helping to optimize memory usage.
Optimized and Unified Data Cache
Caching plays an essential role in StarRocks' high query performance. Previous versions introduced cache preloading, asynchronous population, priority control, and dynamic parameter tuning. In StarRocks 3.4, further enhancements improve cache efficiency and resilience against large, sporadic queries:
-
Segmented LRU (SLRU) Cache Replacement: Introduces eviction and protection segments, both managed by LRU, reducing cache pollution from large ad-hoc queries. This boosts cache hit rates and minimizes performance fluctuations—leading to up to 70%+ query performance gains in tests. Read more here in the StarRocks documentation.
-
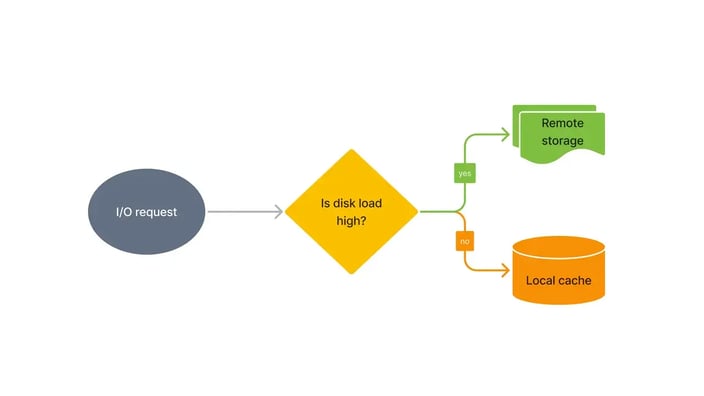
Adaptive I/O Strategy: Dynamically routes some queries to remote storage based on cache disk load, significantly improving throughput under high loads, with 1x–multi-fold performance improvements.
-
Unified Cache Management: Standardizes data cache instances and configuration parameters across shared data and data lake queries, as well as monitors metrics, simplifying setup and optimizing resource utilization—eliminating the need for instance-specific resource reservations.
20% Performance Improvements On TPC-DS
StarRocks 3.4 delivers faster and more efficient query execution. This release introduces optimizations based on common query patterns, including:
-
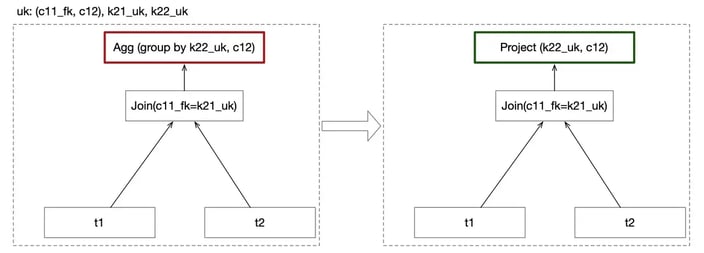
Primary-foreign key-based table pruning to eliminate unnecessary data scans.

-
Aggregation column pruning for improved aggregation efficiency.
-
Optimized aggregation pushdown to further reduce computation overhead.
-
Enhanced multi-column OR predicate pushdown for better filtering performance.
In TPC-DS 1TB Iceberg benchmark tests, these improvements led to a 20% boost in query performance.
Query Plan Optimization with Statistics and Query History
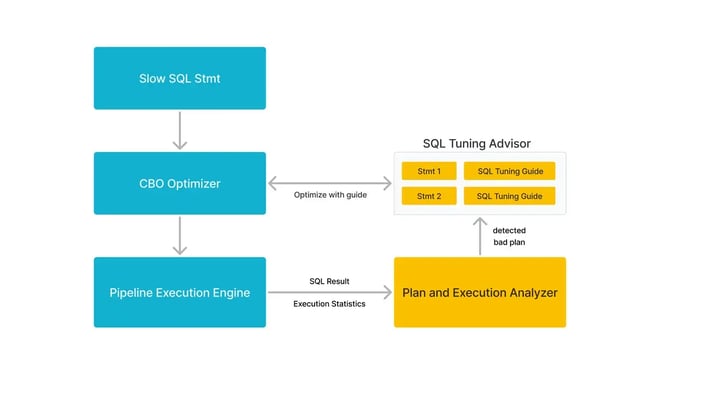
StarRocks 3.4 goes beyond raw query execution improvements by enhancing query optimization with automated statistics collection. It automatically triggers ANALYZE tasks to gather detailed statistics for external tables, providing more accurate NDV (Number of Distinct Values) estimates than traditional metadata files. This leads to better query plans and improved performance.
Additionally, the new Query Feedback feature takes self-optimizing query performance one step further. StarRocks continuously analyzes slow queries, identifies potential inefficiencies in query plans, and may generate automated tuning recommendations. When the system encounters similar queries in the future, it can dynamically adjust execution plans, ensuring queries run faster and more efficiently over time—without manual intervention.
With zero manual intervention, these enhancements ensure that all StarRocks users benefit from smarter, more efficient query execution right out of the box.
Enhanced Data Lake Ecosystem Support
Beyond performance improvements, StarRocks 3.4 continues to expand its Data Lake ecosystem integration.
-
Iceberg Time Travel: Users can now create and delete BRANCH and TAG, as well as query specific data versions using TIMESTAMP or VERSION. This makes it easier to access historical data and recover accidentally deleted records. Additionally, StarRocks supports writing data to different branches, enabling parallel development, testing, and change isolation.
-
Delta Column Mapping: StarRocks now supports querying Delta Lake data with schema evolution.
Create Table
StarRocks 3.4 enhances table creation flexibility and aggregation capabilities with key improvements:
-
Expanded Aggregate Table Functions: Aggregate tables now support nearly all StarRocks aggregation functions through the all new Generic aggregate function states. This also extends to materialized views with query rewrite.
-
Unified and More Powerful Partitioning:Partitioning has been unified into expression partition, now supporting multi-level expression-based partitions. Users can define any expression at each level, enabling more precise data organization based on business needs.
Data Ingestion
StarRocks 3.4 improves data ingestion with simpler bulk imports, smarter partition overwrites, and optimized real-time streaming.
-
INSERT from FILES now supports:
-
LIST remote directories and files: before ingestion, allowing users to easily inspect and validate the data.
-
BY NAME column mapping: automatically aligning file columns with table columns—ideal for wide tables with many matching column names.
-
Union files with different schema: Enables ingestion of files with evolving schemas, ensuring seamless and fault-tolerant data integration in dynamic data environments.
-
New PROPERTIES clauses: adding strict mode, error filtering, and timeout controls for better data quality management during ingestion, see INSERT - PROPERTIES.
-
Dynamic INSERT OVERWRITE: allows automatic partition detection, updating only relevant partitions instead of replacing all data.
-
-
For real-time streaming, the new Merge Commit feature combines multiple small ingestions into a single transaction, improving performance for high-frequency, small-batch data ingestion while reducing system overhead.
Stability & Security
High availability is a core capability of StarRocks’ multi-replica architecture. StarRocks 3.4 introduces the following enhancements to further improve system stability and reliability:
-
Graceful Exit for BE/CN Nodes: Ensures queries continue running briefly when nodes exit, minimizing disruption during upgrades and improving high availability.
-
Enhanced System Stability: [Preview] Follower FE Checkpoint support reduces Leader FE memory pressure, while logging optimizations improve overall cluster reliability.
-
Faster and More Comprehensive Backups: Now supports Logical Views, External Catalogs metadata, and partitions created with expression partitioning and list partitioning strategies, with backup speeds reaching 1GB/s per node.
Learn More About StarRocks 3.4
From vector search and Python UDFs to enhanced query execution and data ingestion, this release makes analytics faster, more scalable, and easier to use.
Want to see it in action? Join our webinar to explore these new features and get your questions answered.
