Semi-structured data types like MAP, STRUCT, JSON, and ARRAY are common in various scenarios due to their expressive capabilities. However, analyzing these data types poses unique challenges compared to structured data. Fortunately, those unique challenges can easily be solved with the use of generated columns.
In this article we'll explain what makes accelerating semi-structured data so difficult and how generated columns can save you significant time.
Challenges With Analyzing Semi-Structured Data
Working with semi-structured data presents a variety of stumbling blocks, but the two primary challenges you're likely to encounter fall under the complex retrieval of data and performing CPU intensive computations
-
Complex Retrieval: Fields within complex data types such as MAP, STRUCT, and JSON are often stored collectively. To analyze a specific field, systems must first extract the entire data item from storage, which can severely impact I/O efficiency.
-
CPU Intensive Computations: Performing OLAP operations (like aggregation and sorting) on semi-structured data directly often requires significant computational overhead, contributing to slower performance and reduced scalability.
How can you sidestep these challenges? One popular approach is with generated columns.
Using Generated Columns With Semi-Structured Data
Generated columns offer a powerful solution to the obstacles presented by semi-structured data. Generated columns are special columns that automatically compute values based on predefined expressions, with results stored in them to accelerate query performance. Here's how they work:
How to accelerate semi-structured data analytics with generated columns
For semi-structured data, complex expressions can be precomputed during the data ingestion process and stored in generated columns. You can see an example of this process in the image below:
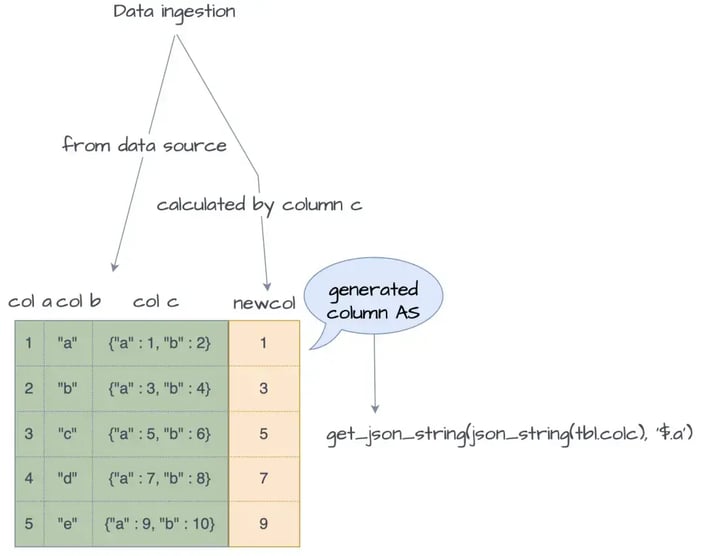
A semi-structured data analytics outline
This approach not only accelerates data retrieval during queries but also reduces computational overhead, significantly accelerating performance and addressing the majority of problems faced by users working with semi-structured data.
Practical Implementations of Generated Columns
Let's use StarRocks as an example to better illustrate the capabilities of generated columns. StarRocks, a high-performance real-time OLAP database for subsecond queries at scale, introduced its generated column feature in its version 3.1 release. This production-ready implementation has many features built specifically to simplify usage and accelerate performance. One such capability is StarRocks' query rewrite functionality for generated columns.
Query rewrite for generated columns
To retrieve the results of expressions stored in generated columns, the generated column name needs to be specified in the SQL query. However, this method requires adjustments to existing SQL, a tedious process.
To avoid this, StarRocks supports automatic query rewriting for generated columns. During execution plan generation, its SQL optimizer checks all expressions in the SQL and rewrites those bound to generated columns to query the generated column fields instead.
For example, if a query needs to retrieve the 'a' field from the 'colc' column, the query would typically be:
SELECT get_json_string(json_string(tbl.colc), '$.a') FROM tbl;
And the process would look like this:
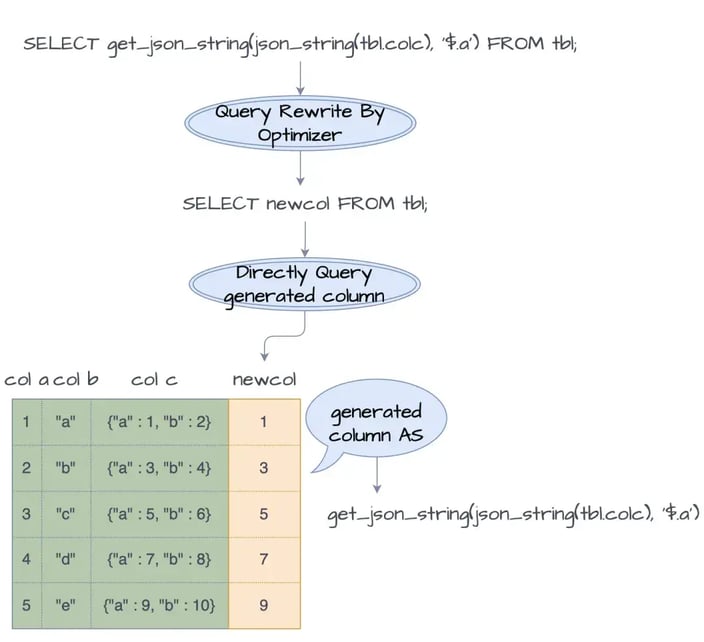
Query process for generated columns
The optimizer will automatically rewrite this expression to query the generated column value, which accelerates the query seamlessly.
Efficiently adding generated columns:
Adding generated columns to existing tables can become a frequent operation. For instance, a performance bottleneck in an expression calculation might be identified, prompting the addition of a generated column for query acceleration on demand.
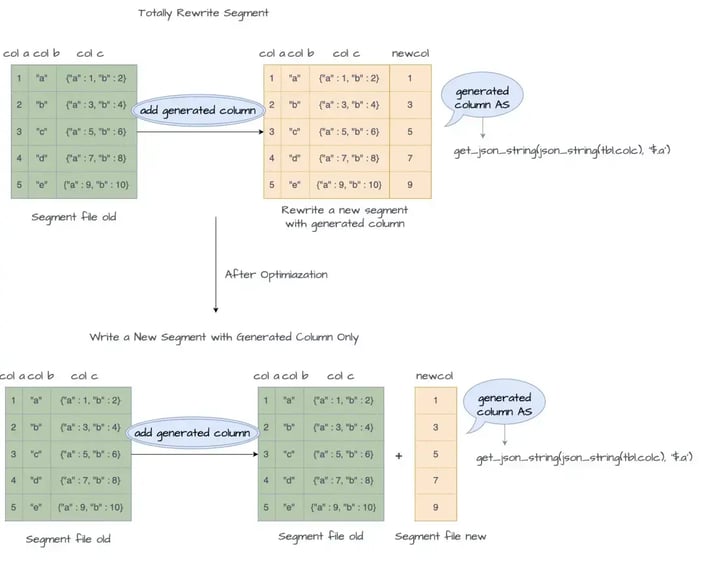
Efficient generated columns
To facilitate this kind of frequent use, StarRocks does not trigger rewriting existing physical files when adding generated columns to existing tables. Involving only an update to the metadata, read I/O costs are associated only with the columns referenced in the generated expression, and the write I/O costs involve only the results of the expression for the generated column. This approach significantly improves the I/O efficiency of schema changes, supporting added generated columns on demand for query acceleration.
Generated Column Performance Benchmarks
To verify the acceleration effects of generated columns on semi-structured data analysis, we a few benchmark tests to showcase the impact. Below you'll find the methodology, queries, and results, so you can test for yourself if you wish.
Environment
Create table
CREATE TABLE `t` (
`id` bigint(20) NOT NULL COMMENT "",
`array_int` ARRAY<int(11)> NOT NULL COMMENT "",
`json_data` json NOT NULL COMMENT "",
`gc_1` double NULL AS array_avg(`test`.`t`.`array_int`) COMMENT "",
`gc_2` ARRAY<int(11)> NULL AS array_sort(`test`.`t`.`array_int`) COMMENT "",
`gc_3` varchar(65533) NULL AS get_json_string(json_string(`test`.`t`.`json_data`), '$.a') COMMENT ""
) ENGINE=OLAP
PRIMARY KEY(`id`)
COMMENT "OLAP"
DISTRIBUTED BY HASH(`id`) BUCKETS 48
PROPERTIES (
"replication_num" = "1",
"in_memory" = "false",
"storage_format" = "DEFAULT",
"enable_persistent_index" = "false",
"replicated_storage" = "true",
"compression" = "LZ4"
)
Regular columns:
-
id, serves as the primary key column to ensure uniqueness. -
array_int, an ARRAY<int> with a length of 10,000, containing random numbers. -
json_data, containing two keys: key "a" has an integer value of 1, and key "b" has a value that is a string composed of 100 UUIDs.
Queries
-- q1
SELECT get_json_string(json_string(json_data), '$.a') FROM A
-- q2
SELECT array_avg(array_int) FROM A;
|
Query
|
Directly Query JSON (s)
|
With Generated Column (s)
|
|
Q1
|
0.80
|
0.18
|
|
Q2
|
247.8
|
0.28
|
From the test results above, we can conclude:
-
q1: By using a generated column to extract a subfield from a large JSON field, the I/O cost of reading the JSON field during the query phase was significantly reduced, resulting in a performance improvement of more than 4x.
-
q2: Using a generated column for aggregating a large ARRAY field (calculating the average) not only saves on the I/O costs of reading this semi-structured data field during the query phase, but also significantly reduces the CPU consumption associated with ARRAY aggregation calculations, achieving a hundredfold performance improvement.
Try Generated Columns For Yourself
It's clear that generated columns are an effective means to accelerate semi-structured data analysis. By using generated columns, users can significantly reduce the I/O and CPU resource consumption associated with complex expressions during queries, achieving up to a hundredfold performance improvement in various scenarios.
Now that you're familiar with generated columns, try them for yourself. You can learn more about StarRocks' specific generated column implementation in its documentation, and get started quickly with help from the community in the StarRocks Slack channel.
