Our company is a designer and manufacturer of consumer electronics and related software, home appliances, and household items. The e-commerce platform we talked about in this article is a boutique lifestyle e-commerce platform. The Data Center is in charge of the platform's digital assets to perform data analytics, leading to more effective decision-making and more revenue, thus requiring even more analytics.
Historical Structure and Business Pain Points
Limited by previous technology and scale of business, we have a data center structured like this.
Business and traffics data were gathered and transmitted to Talos. The real-time data would go through an ETL process via Apache Spark™ Streaming. Product data would be recorded into MySQL after aggregation. Other data would be aggregated in Apache Druid®. Offline data would be recorded into Apache Hive™. Querying services would be offered via Apache Spark™ SQL.
This framework, however, could not meet users' demands as the business develops rapidly.
- As data explodes, the performance of queries is at a bottleneck.
- The costs of machines and maintenance are high when operating multiple systems.
- Apache Druid is not suitable for storing and querying detailed data.
Application of StarRocks
A Study of OLAP Engine
We have studied a handful of OLAP engines thoroughly, none of them could meet the demand of querying precisely and flexibly in large-scale data. Thus we have chosen StarRocks as our new OLAP engine after deliberation. These strengths are what we value:
- Top-class query performance:Its performance of single table query and multi-table join query being optimized by CBO outperforms ClickHouse.
- It supports both duplicate and aggregate key models, including Duplicate/Aggregate/Primary Key model and materialized view.
- Efficient data import: StarRocks is efficient in both streaming and batch ingestion.
- Easy operation and maintenance, high availability: high availability is supported by multiple replicas and consistent protocol. Also, StarRocks supports self-healing and auto-rebalance.
Current Framework
The figure above show our framework after we use StarRocks:
- Business and traffics data would be written into Talos through data acquisition service;
- Real-time data would be extracted, transformed, and loaded via Apache Flink®, then written into StarRocks;
- Offline data would be written into Apache Hive and imported into StarRocks through the same ETL process;
- StarRocks serves as the only OLAP engine, making the framework more simple.
Data Writing
- The data would be first written into STG, the buffer layer, including Binlog of orders, discounts, refunds, and traffic logs.
- Analyzation will be completed in ODS layer, while ETL will be completed in DWD layer with business logic.
- In DWS layer, data will be initially aggregated in accordance with their theme and dimension.
- Finally, all data will be written into StarRocks.
StarRocks so far includes aggregation models concerning Stock Keeping Unit, Interface, Discount, Details and Dimensions. Aggregate data would apply to aggregate key model, duplicate key model is for detailed data, materialized view would enhance the process, offline data could be imported via broker load, real-time data via stream load.
Through our half-year efforts, StarRocks is connected to every major platform in our company. The data could be extracted from Apache Flink, Apache Hive, Apache Hadoop, Apache Kafka, Apache Spark, MySQL and written into StarRocks. Data on StarRocks could also be transported to platforms such as Apache Flink, Apache Hive, Apache Hadoop, Apache Spark and Presto.
Data Modeling
We primarily used flat tables in modeling, putting the indicator columns and dimension columns on the same table. The serious problem was that we needed to backtrack the data and re-aggregate the calculation when the dimension was modified, which was very time-consuming.
Thanks to StarRocks' outstanding multi-table join performance, we have changed the form of flat tables in the past and adopted star schema for modeling, allowing dimensions changes, thus reducing backtracking costs.
Data Query
Apache Druid was mainly used to calculate distinct count. Since Apache Druid uses the HLL approximation algorithm, the accuracy of distinct count can only reach 97% to 99%, which can no longer meet the demand in scenarios such as AB tests and algorithm effect evaluation. StarRocks supports bitmap to calculate distinct count, improving the accuracy to 100%.
Compared with the traditional broadcast and partition shuffle join, StarRocks offers colocate join and bucket shuffle join algorithms. Colocate join ensures that the data of multiple tables is distributed according to the bucket key and is consistent when data is written, so that multiple tables can be joined locally, reducing data transportation and improving query performance. In production practice, we found that it can bring a powerful increase of more than 3-4 times of product performance.
Also, bucket shuffle join is widely used in StarRocks. Compared with broadcast and partition shuffle join that would transport data of multiple tables, bucket shuffle join only needs to transport data of the right table. So, when Join Key includes the bucketing column of the left table, bucket shuffle join only transports data of the right table to the node that contains data of the left table, reducing the costs of data transmission between nodes and speeding up queries. It has been proved that bucket shuffle join can improve query performance by more than 2 or 3 times.
Compared with the previous architecture, the query performance of the current architecture is significantly improved.
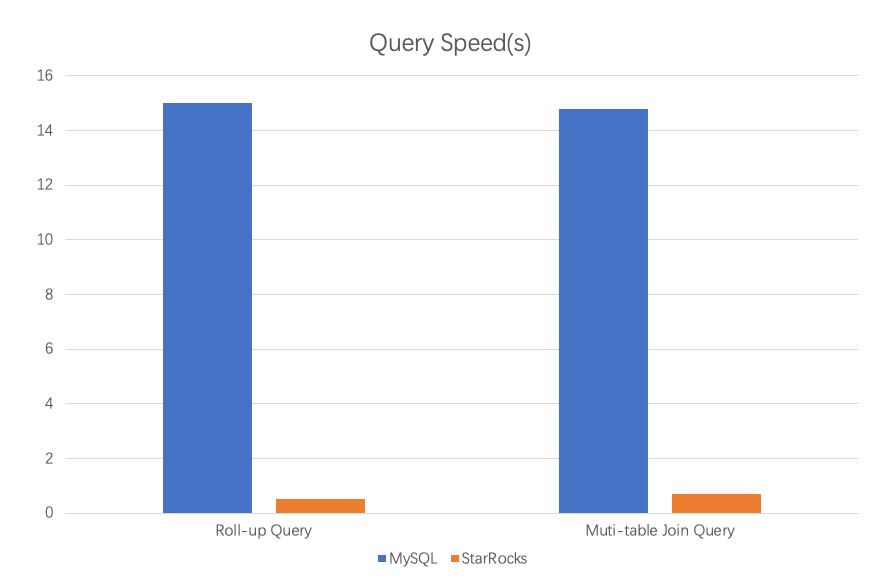
- Roll up and multi-table join queries: 20-30 times faster compared to MySQL-based architecture.
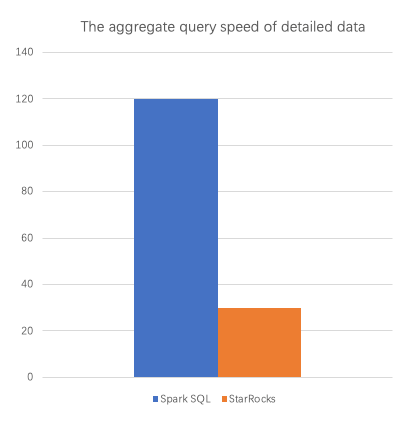
- The aggregate query of detailed data: 4 times faster compared to Apache Spark SQL
- The storage cost: reduced to 1/3 of the MySQL+Apache Druid solution.
Summary
First, StarRocks is simple and cost-effective. The duplicate and aggregate models are suitable for most scenarios, making StarRocks the only engine to replace the multiple engines previously used in the data center architecture. Also, StarRocks' streamlined architecture makes it easy to operate and maintain, and reduces machine costs by more than 50% compared to Apache Spark.
Second, StarRocks has superior query performance. StarRocks' near-real-time query performance and various features optimized for many typical scenarios (colocate shuffle Join, bucket shuffle Join, CBO, etc.) bring a better experience to users.
Third, StarRocks allows data to be stored and computed together or separately. Currently, storage and compute are coupled in StarRocks. In future releases, the two will be decoupled by creating external tables in order to access data stored in Elasticsearch, MySQL, and Apache Hive. Decoupled storage and compute allows StarRocks to efficiently connect with the Apache Hadoop ecosystem at a low cost.
Apache®, Apache Spark™, Apache Flink®, Apache Kafka®, Apache Hadoop®, Apache Hive™, Apache Druid® and their logos are either registered trademarks or trademarks of the Apache Software Foundation in the United States and/or other countries.
