What is Apache Druid?
What is StarRocks?
Apache Druid vs. StarRocks: Exploring the Differences
Apache Druid is a popular open-source distributed analytical database that is well-suited for real-time analytics and ad-hoc queries on large datasets. However, there are a few negatives with Apache Druid, including:
- Limited support for JOINs: Druid is not designed for JOINs, and it can be very inefficient when performing JOINs on large datasets. Additionally, Druid requires data to be denormalized, which can add complexity and overhead to the data pipeline.
- Lack of supporting streaming data: If you need low-latency updates of existing records using a primary key, however, you may need an Apache Druid alternative. Druid supports streaming inserts but not streaming updates. Updates must be performed via background batch jobs; updating Druid is costly and can impact performance. If you need to make frequent updates to your data, Druid may not be for you unless you can adjust your update process.
- Limited indexing capabilities: In Druid, you never see a "create index" statement. Instead, Druid automatically (bitmap) indexes all data.
- Steep learning curve: Druid can be complex to set up and manage, and it can take some time to learn how to use it effectively.
- Lack of some features: Druid lacks some features that are common in other analytical databases, such as support for ACID transactions and window functions.
StarRocks address these issues by:
- JOINs: StarRocks supports all types of JOINS like inner, outer, co-located, lateral, shuffle join and broadcast joins. Lots of options. Ultimately, having the ability to do JOINS means that less data pipeline engineering to move data from various system to StarRocks.
- Streaming insert and upserts: With our primary key table, you can treat this table just like an OLTP table. Just use the mysql driver and do your inserts like you would normally do in an OLTP database.
- More indexing options: StarRocks supports bitmaps (you pick the columns) and other options like Bloom Filter. As a result, it's very "tunable".
- Learning curve: StarRocks has a streamlined deployment architecture. It really is 2 types of nodes, front end node (FE) that provides the SQL service and the backend node (BE) that processes and stores the data. You can scale each tier independently of each other.
- ACID for data ingestion: StarRocks supports ACID for data ingestion. It either all commits or all rollbacks.
Apache Druid vs. StarRocks: Benchmark Comparison
We performed a test on 99 queries against a the SSB 100GB dataset. We used StarRocks and Apache Druid to query the same copy of data.
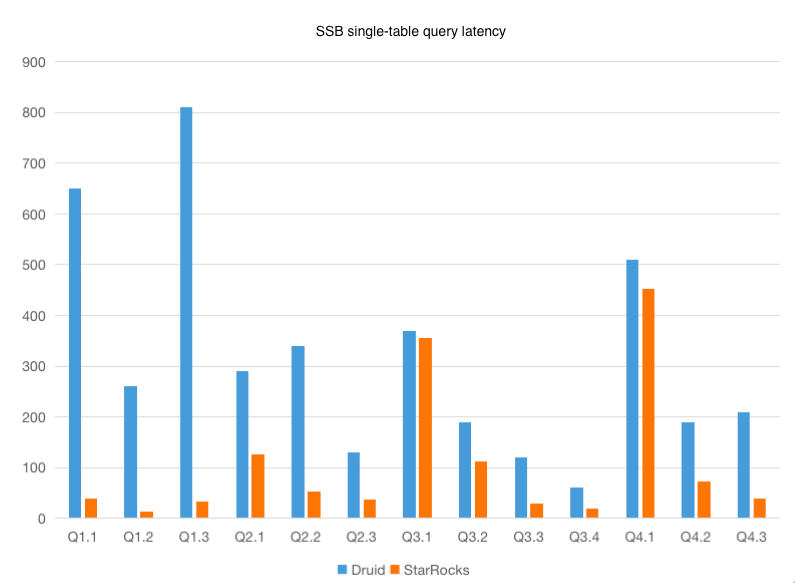
The test results show that StarRocks has better performance in the SSB 100 GB single-table test. Among the 11 queries, StarRocks outperforms Apache Druid by a large margin in 9 queries.
Apache Druid uses lookup and join to implement multi-table association. Apache Druid®join supports only broadcast hash joins and tables except the leftmost table must be able to be stored in memory. It has some limitations but lacks optimizations. This test uses Apache Druid lookups that have relatively good performance for the multi-table association. In actual implementation, lookup functions outperform lookup table joins. Therefore, this test uses lookup functions for the multi-table association.
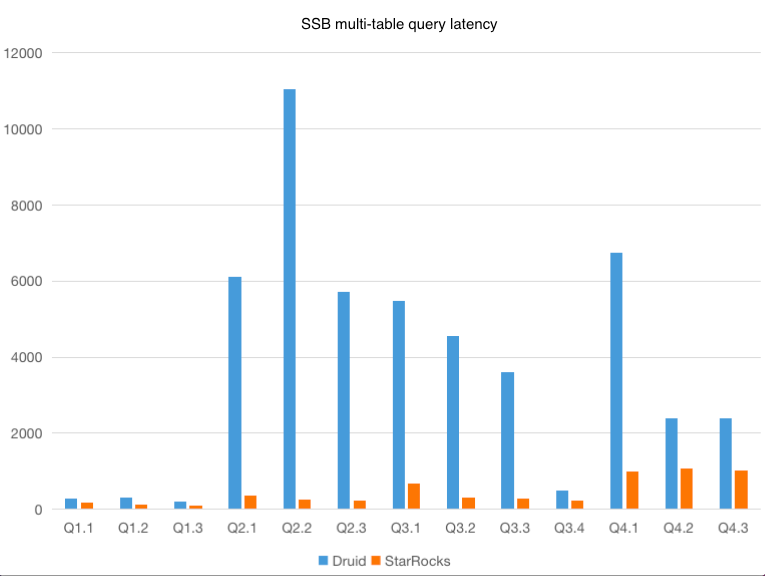
The test results show that StarRocks has better performance in multi-table association. Apache Druid® lookup pre-loads table data to the memory of each node. It has advantages in scenarios where dimension tables contain only a moderate volume of data and frequent shuffling operations are not required. However, Apache Druid® lookup can only be used for simple key-value mapping.
Apache Druid vs. StarRocks – Which to choose?
When is StarRocks a fit?
- Performance: In our testing, for normalized and denormalized data, StarRocks had better performance.
- Data pipeline simplification: Having a database that support JOINS means less not having to do the work from moving a OLTP normalized table design set to a OLAP flat table design.
- Cost Saving: Save people time (data engineering) and storage costs (data duplication as a result of denormalization).
- Real time streaming: StarRocks support insert and upserts. No need for a complicated process to support upserts.
- SQL wire compatible protocol: Connect to anything and everything that supports the mySQL driver. Not Druid SQL.
- Data Lakehouse: StarRocks also has the ability to query data in many different open table formats like Apache Iceberg, Apache Hive, Delta Lake and Apache Hudi. Apache Druid only supports read for Apache Iceberg and Apache Hive.
When is Apache Druid a fit?
- I need a product that has been in the market longer. I like that they have reference customers like Netflix, Airbnb and Uber.
Use cases: Apache Druid vs. StarRocks
Try out our hands on lab!
One of the best way to understand our product is through our hands on labs at https://killercoda.com/starrocks/
