In this post, I want to compare Trino, the popular distributed query engine that runs analytical queries over big volumes of data with interactive latencies with StarRocks.
Sources of Information
I asked StarRocks committers (Heng Zhao, StarRocks TSC member; Dorian Zheng, StarRocks Active Contributor). As far as Trino, we used the Trino website and google search to research various topics. We compared the latest release of both products as of Oct 2023.
The Rise of Trino/Presto
Initially, Presto was conceived and developed at Facebook (now known as Meta) to enable their data analysts to execute interactive queries on their extensive Apache Hadoop data warehouse. The project, spearheaded by Martin Traverso, Dain Sundstrom, David Phillips, and Eric Hwang, began in 2012 as a solution to overcome the limitations of Apache Hive, which was previously used for SQL analytics on Facebook's voluminous data warehouse but was found too sluggish for the company's expansive data needs. Presto was publicly deployed at Facebook in the same year and later made open source in November 2013.
In 2013, when it came out, it had some major advantages.
-
Could handle large datasets and complex queries efficiently (compared to other available technology at the time).
-
Specifically, much faster than MapReduce technology like Apache Hive, which was the incumbent at the time.
-
Could connect to many different data sources.
-
Specifically, connect to multiple databases of the same type with the option to join datasets across databases (e.g. horizontal scaling of database instances).
-
-
-
Could scale to meet the needs of large organizations.
-
Facebook proved Presto could work, and other tech unicorns quickly adopted it for their data warehouse needs.
-
-
Open Source
-
Who doesn't like someone else to do R&D and software engineering for a low cost of "free"?
-
The Presto project underwent significant changes over a decade. In 2018-2019, following the departure of the original founders from Facebook, the project split into two forks: PrestoDB and PrestoSQL. This division was a response to the evolving needs and direction of the Presto community.
Trino emerged from the PrestoSQL fork. In January 2021, PrestoSQL was rebranded as Trino, marking a distinct evolution in the project's trajectory. Trino maintained its roots in large-scale data processing, adopting a Massively Parallel Processing (MPP) architecture and being developed in Java. This distinguished it from traditional map-reduce frameworks, enhancing its ability to efficiently handle and process large data volumes.
The Change in the Users' Requirement
Since the advent of Trino/Presto, they have satisfactorily met most users' needs in data analysis at the time. However, it is noteworthy that users' requirements for data analysis are still constantly changing and evolving. This is particularly evident after the world has been dominated by mobile internet and SaaS applications, with User-facing Analytics and Real-time Analytics becoming important trends for enterprises.
The main manifestations of this trend are as follows:
-
Enterprises hope to have more high-performance query engines to meet the demand for low-latency queries on massive amounts of data. No user wants to wait more than three seconds in front of a screen.
-
Enterprises need the capacity to support hundreds, or even thousands, of people conducting data queries and analyses simultaneously. The continuously increasing number of users has spurred this demand.
-
Enterprises aim to achieve timely analysis of the latest data and use the analysis results to guide subsequent work.
-
In the current post-pandemic era, how to save costs and improve work efficiency in such an adverse economic environment? That is another question every enterprise needs to answer.
It is precisely because of these new trends that several database engineers initiated a new database project in 2020, named StarRocks, and officially opened its source code in September 2021. StarRocks was donated to the Linux Foundation at the beginning of 2023. Although it hasn't been established for long, the influence of StarRocks seems to be growing rapidly. Currently, hundreds of large enterprises around the world are using StarRocks in production environments.
-2.png?width=774&height=488&name=1280X1280%20(1)-2.png)
Looking at the use cases, StarRocks and Trino/Presto have a considerable degree of overlap. Simply put, StarRocks is more suited for user-facing scenarios with low latency, while Trino/Presto is more suitable for analytical scenarios that involve fetching data from multiple data sources simultaneously.
Similarities Between Trino and StarRocks
StarRocks and Trino have many similarities in terms of technical features.
Massively Parallel Processing (MPP)
Both engines adopt MPP as their distributed execution framework. In this framework, a query request is split into numerous logic and physical execution units and runs simultaneously on multiple nodes. Unlike the scatter-gather pattern used by many other data analytics products in their distributed computing framework, MPP can utilize more resources to process query requests. Because of this framework, both engines can be used on petabytes of data, and hundreds of giants have already used these engines in their production environments.
Cost-based Optimizer (CBO)
Both engines have Cost-based Optimizer. In multi-table join queries, in addition to the execution engine, optimized execution plans can also play an essential role in improving query performance. Because of the CBO, both engines can support a variety of SQL features, including complex queries, joins, and aggregations. Both Trino and StarRocks have passed TPC-H and the more difficult TPC-DS benchmark.
Pipeline Execution Framework
Both engines have Pipeline execution framework. The primary goal of the Pipeline execution framework is to enhance the efficiency of how a query engine utilizes multi-core resources on a single machine. Its main functions encompass three aspects:
-
Reduce the cost of task scheduling for various computing nodes in the query engine.
-
Increase CPU utilization while processing query requests.
-
Automatically adjust the parallelism of queries execution to fully leverage the computational power of multi-core systems, thereby enhancing query performance.
ANSI SQL Support
Both engines are ANSI SQL compliant. That means that analysts can use the query language that they are most familiar with for their daily work without the need for additional learning costs. The BI tools that enterprises often use will also integrate very easily with StarRocks or Trino.
Differences Between Trino and StarRocks
Although there are some similarities in technical implementation, we can also see some clearly different technical characteristics between these two kinds of systems.
Vectorized Query Engine
.png?width=2076&height=472&name=whiteboard_exported_image%20(1).png)
StarRocks is a Native Vectorized Engine implemented in C++, while Trino is implemented in Java and uses limited vectorization technology. Vectorization technology helps StarRocks utilize CPU processing power more efficiently. This type of query engine has the following characteristics:
-
It can fully utilize the efficiency of columnar data management. This type of query engine reads data from columnar storage, and the way they manage data in memory, as well as the way operators process data, is columnar. Such engines can use the CPU cache more effectively, improving CPU execution efficiency.
-
It can fully utilize the SIMD instructions supported by the CPU. This allows the CPU to complete more data calculations in fewer clock cycles. According to data provided by StarRocks, using vectorized instructions can improve overall performance by 3-10 times.
-
It can compress data more efficiently to greatly reduce memory usage. This makes this type of query engine more capable of handling large data volume query requests.
In fact, Trino is also exploring vectorization technology. Trino has some SIMD code, but it's behind compared to StarRocks in terms of depth and coverage. Trino is still working on improving their vectorization efforts (read https://github.com/trinodb/trino/issues/14237). Meta's Velox project aims to use vectorization technology to accelerate Trino queries. However, so far, very few companies have formally used Velox in production environments.
Materialized View
.png?width=2188&height=476&name=whiteboard_exported_image%20(2).png)
StarRocks has several materialized view features that Trino does not have. The materialized view is an advanced way to accelerate common queries. Both StarRocks and Trino support creating materialized views however, StarRocks has the ability to
-
Automatically re-write queries to enhance query performance. That means StarRocks automatically selects suitable materialized views to accelerate queries. The users don't need to rewrite their SQLs to make use of the materialized views.
-
Execute partition-level materialized view refresh, which allows the user to have better performance and scalability while reducing resource consumption.
-
Have the option of writing materialized views to the local disk instead of back to remote disk/storage. That means the users can leverage the high performance of the local disk. Local storage utilizes StarRocks' proprietary columnar storage format, which better supports the execution of the vectorized query engine.
Trino currently doesn't have these features:
-
It doesn't have automatic query rewrite features. The user needs to spend a lot of time on query rewriting.
-
It needs to execute full-table materialized view refreshes when the data is changed.
-
It can not write materialized views on the local disk.
There is an ongoing discussion on how to improve the materialized view "fresh-ness".
Cache System
.png?width=1516&height=1100&name=whiteboard_exported_image%20(3).png)
The cache system in StarRocks is more complicated than Trino's. StarRocks implements a cluster-aware data cache on each node. This cache utilizes a combination of memory and disk that can be used for intermediate and final query results. As a result of this component, StarRocks has the ability to cache Apache Iceberg metadata on local disks for better query performance. StarRocks also support warming up the cache, setting cache priorities, and setting cache blacklists.
StarRocks' query cache significantly enhances query performance in high-concurrency scenarios. It functions by caching the intermediate results of each computing node in memory for subsequent reuse. Query cache is different from the conventional result cache. While the result cache is effective only for identical queries, the query cache can also accelerate queries that are not exactly the same. According to tests by StarRocks development engineers, the query cache can improve query efficiency by 3 to 17 times.
Trino's cache system is only on the memory level. This makes it very fast, and puts on a need for more numerous and larger memory virtual machine instances. There is work to support local disk caching for "hot cache". Read more at https://github.com/trinodb/trino/pull/16375 and https://github.com/trinodb/trino/pull/18719
Join Performance
.png?width=2512&height=486&name=whiteboard_exported_image%20(4).png)
Both Trino and StarRocks can support complex Join operations. However, StarRocks is capable of delivering higher performance. This is because, in addition to a vectorized query engine, StarRocks also possesses some special technical capabilities.
Join reordering is a technique that can be used to improve the performance of database queries that involve multiple joins. It works by changing the order in which the joins are executed.
The cost of executing a join query depends on the size of the tables being joined and the order in which the joins are executed. By reordering the joins, it is possible to find a join plan that is more efficient. Join reordering can be performed by the optimizer, or it can be specified manually by the user. The optimizer will typically try to reorder the joins to minimize the cost of the query.
There are a number of different algorithms that can be used to reorder joins. Some of the most common algorithms implemented by StarRocks include:
-
Greedy algorithm: The greedy algorithm works by repeatedly selecting the pair of tables that has the lowest join cost and joining them together.
-
Dynamic programming algorithm: The dynamic programming algorithm works by building a table that contains the cost of joining each pair of tables. The algorithm then uses this table to find the optimal join plan.
-
Exhaust algorithm: A technique for performing data joins that is particularly well-suited for large datasets. It works by breaking down the join operation into smaller, more manageable tasks. This makes it possible to perform joins on datasets that are too large to fit in memory.
-
Left-deep join reordering: A heuristic algorithm used to optimize the order of joins in a query. The algorithm works by recursively building a left-deep join tree, where each node in the tree represents a join operation. The algorithm starts with the smallest table and then recursively joins it with the next largest table, until all of the tables have been joined.
-
Join Associativity algorithm: A technique for optimizing the order of joins in a query. It works by exploiting the associativity property of joins, which states that the order of joins can be changed without affecting the result.
-
Join Commutativity algorithm: A technique for optimizing the order of joins in a query. It works by exploiting the commutativity property of joins, which states that the order of join operands can be changed without affecting the result.
Overall, StarRocks implements (at last count) 5 more algorithms than Trino.
Another major feature of StarRocks for Join performance is the runtime filter. Runtime filtering is a technique that can be used to improve the performance of data join operations. It works by filtering out rows from one table before they are joined with another table, based on the join condition. This can significantly reduce the amount of data that needs to be processed, which can lead to significant performance improvements.
-
Support Local And Global Runtime Filter
-
Shuffle Aware
-
Push down Max/Min, In Filter To Storage Engine
-
Cost Estimation Based
-
Support Runtime Filter Cache
-
Push Runtime Filter To Two Sides
-
SIMD Bloom Filter
-
Adaptive Join Runtime Filters Selection
-
Support multi column runtime filter
Finally, StarRocks can support co-located join. A co-located join is a type of join in which the tables being joined are stored on the same nodes of a distributed database cluster. This can significantly improve the performance of the join operation, as the data does not need to be transferred between nodes to be processed.
High Availability
StarRocks has two types of nodes, each capable of achieving high availability through specific strategies. Front End nodes are stateless, and high availability can be achieved by deploying an odd number of Front End nodes. These nodes use the Raft protocol for leader election among themselves. Back End nodes support a multi-replica mechanism, ensuring that the failure of any node does not affect the system's operation. Therefore, StarRocks can implement hot upgrades of the system. During system upgrades, the online services of the system will not be affected.
Trino does not have built-in high availability (HA) support. Trino's coordinator is a single point of failure in the system. If this node fails, the entire system becomes unavailable. This means that whenever the system is upgraded, Trino's online services need to be halted for a period of time. So far, the Trino project has not offered a solution to this issue. Read more at https://github.com/trinodb/trino/issues/391.
Data Sources and Open Table Formats
As advocates of the Data Mesh concept, the Trino community has always been dedicated to integrating more data sources. So far, Trino has developed over 60 different connectors, enabling connections to various data sources, including relational databases, data lakes, and others. This allows Trino to act as a unified query engine for enterprises, facilitating joint analysis of data from different sources. This is especially useful for larger enterprises with multiple businesses and diverse data sources. Currently, StarRocks is more focused on querying Open Data Lakes and has fewer connectors for other data sources.

StarRocks supports read for both Apache Iceberg, Apache Hudi, Apache Hive, and Delta Lake. StarRocks also supports limited writing abilities on Apache Iceberg. Benchmark testing shows that StarRocks is faster as a query engine for data lakes. Trino supports reading and writing for both Apache Iceberg, Apache Hudi, Apache Hive, and Delta Lake. According to StarRocks' roadmap, the ability to write on the open data lakes will be enhanced soon.
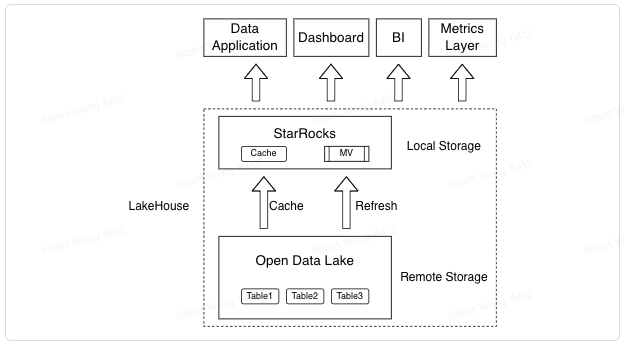
StarRocks' Data Lakehouse Capability
It is precisely because of these unique technical features that StarRocks can provide users with a more complete Lakehouse experience. Utilizing StarRocks to directly query data lakes can achieve performance comparable to that of data warehouses. This enables many business applications to be built directly on data lakes, eliminating the need to import data into data warehouses for analysis. StarRocks' Cache system can use the local storage of computing nodes to cache data, transparently accelerating query performance. Users do not need to build additional Pipelines to manage data transfer.
In some user-facing data analysis scenarios, where lower query latency and higher query concurrency are required, StarRocks' materialized views play a significant role. Materialized views not only speed up related queries by utilizing the local storage of computing nodes, but also their data updates are automatic, requiring no manual intervention. Furthermore, the auto-rewrite feature of materialized views allows users to enjoy the accelerated effects of the views without rewriting any SQL.
Through the combination of various unique technologies, StarRocks truly achieves a user-friendly and high-performance open-source Lakehouse.
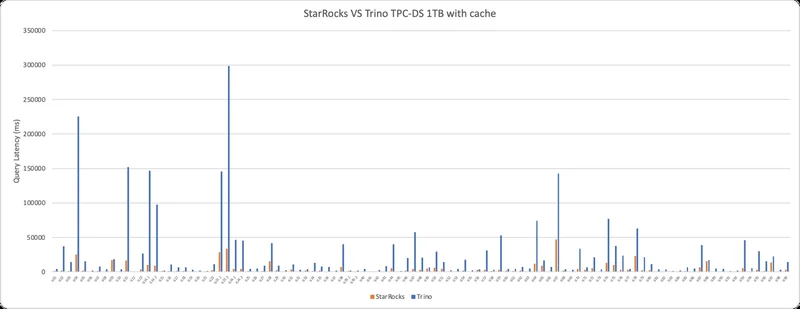
Benchmark
The StarRocks team did a benchmark test on the TPC-DS 1TB dataset. They used StarRocks and Trino to query the same copy of data that is stored in Apache Iceberg table format with Parquet files. The result is that Trino's overall query response time is 5.54x slower than that of StarRocks.
Conclusion
Trino/Presto is a very famous open-source query engine. When enterprises have multiple data sources and need to analyze data from these sources in a unified manner, Trino is an appropriate choice. Compared to Trino, StarRocks is an emerging open-source query engine with many innovative and unique designs. Using StarRocks as a query engine for data lakes, customers can easily achieve a high-performance querying experience. Moreover, customers can use various methods to further accelerate queries, achieving lower latency and higher concurrency. StarRocks is also an excellent choice for querying data lakes.
Glossary
Please see https://github.com/StarRocks/starrocks/discussions/36574
