The open Lakehouse architecture provides compatibility, flexibility, and easier data governance. However, its adoption of high-demand workloads—like low latency, high concurrency, and customer-facing applications—remains limited due to performance challenges.
A primary factor is the remote storage of data, which introduces additional I/O costs and performance bottlenecks, especially when managing numerous small files. Fortunately, caching can be an effective solution to bridge this performance gap. This article will explore caching strategies for open lakehouses and how industry leaders practice them.
Not All Caches Are Effective Solutions
While caching can significantly boost query performance, not every implementation is a silver bullet. Simply adding a cache layer can introduce complexities that may undermine its benefits:
-
Data Consistency Issues: When data changes frequently, maintaining consistency between the cache and the underlying storage can become problematic, especially in distributed environments.
-
Resource Allocation Issues: Caching easily allocates significant disk space, which can't be easily repurposed during peak demand. This rigidity can limit system flexibility and hinder resource scaling when workloads spike.
-
Performance May Not Improve: Writing data to the cache can slow down the system. When the number of cached files grows, it increases system overhead and chances for locking issues. If the system is already under high disk pressure, cache operations can become a bottleneck rather than an optimization.
-
Increased Operational Costs: Deploying and maintaining a cache layer involves additional complexity, which adds to the operational burden and escalates costs.
Caching for Customer-Facing Workloads on Open Lakehouses
An effective caching strategy goes beyond simply relying on a cache; it must balance performance improvements while minimizing complexity and overhead. Here’s what an optimal caching solution should include:
-
Ensuring Data Consistency: Avoid serving outdated data by incorporating mechanisms that use metadata to monitor data freshness. This helps maintain accuracy in query results even when data changes frequently.
-
Scalable and Adaptive: The cache should be flexible enough to adapt to the system's available resources. Ideally, it expands during low-demand periods to cache more data and contracts when disk pressure increases, ensuring that it doesn’t negatively impact overall system performance.
-
Smart Eviction Policy: Not all data should be treated equally. Frequently accessed data needs to stay cached, while infrequent or “cold” queries should not affect the cache’s efficiency. Intelligent data eviction policies are crucial to keep the cache populated with the most relevant data.
-
Flexible Reads: Depending on disk performance, the cache should be able to switch between local and remote reads, optimizing query speed under varying conditions. This adaptability helps prevent the cache from becoming a bottleneck when local disk resources are constrained.
-
Reduced Overhead: Minimizing the overhead associated with caching is key. The system can maintain high query performance without significant resource drain by reducing direct file operations and using asynchronous caching processes.
StarRocks: An Example of Effective Caching
Building an efficient caching system is a complex task that requires both optimized file structures and adaptive mechanisms to handle real-time conditions. StarRocks offers a practical example of achieving this in open data lake environments.
What is StarRocks?
StarRocks is an open-source MPP (Massively Parallel Processing) lakehouse query engine, designed to handle warehouse-like workloads on open data lakes. It supports popular table formats such as Iceberg, Delta, and Hudi, along with file formats like Parquet and ORC. With its advanced features and optimizations for open lakehouses, StarRocks tackles common performance challenges, where caching plays a pivotal role.
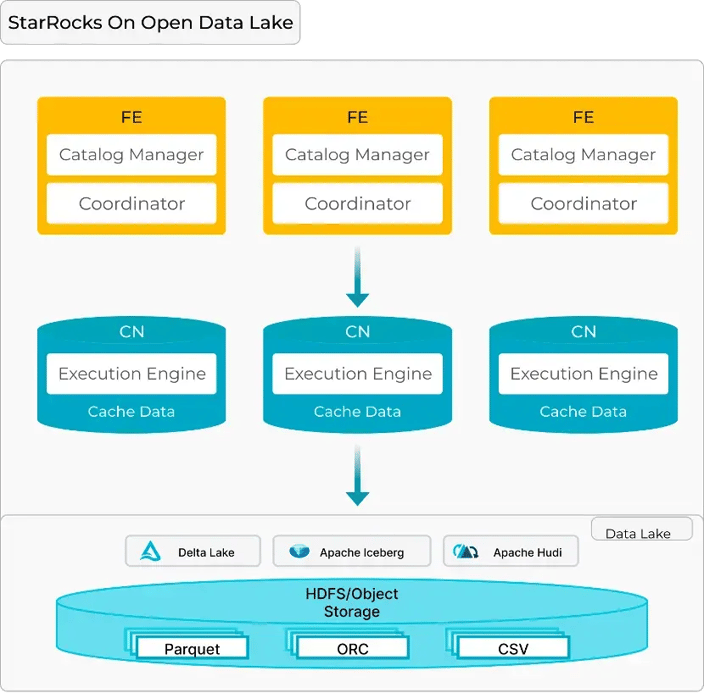
Figure 1: StarRocks on open data lakehouse
StarRocks’ architecture is simple yet effective. It consists of Frontend (FE), which manages metadata and query planning, and Compute nodes (CN), which handle data processing and caching.
When a query is submitted, the CN nodes check if the data is cached and confirm its freshness using metadata, ensuring consistent and fast execution.
With this in mind, let’s dive into how StarRocks handles caching to deliver optimized performance.
How does StarRocks handle caching?
-
Efficient Cache Structure Rather than relying on traditional small files, StarRocks uses large files divided into blocks, with metadata managed by the compute nodes (CN). This approach reduces the overhead of handling numerous small files, significantly improving cache read/write efficiency and overall performance.

Figure 2: StarRocks cache structure
-
Advanced Optimization Strategies StarRocks employs a two-tier caching strategy, leveraging both memory and disk to store frequently accessed "hot" data in faster storage. This boosts performance for high-demand queries. For cache eviction, it uses the SLRU (Segmented Least Recently Used) algorithm, which prioritizes keeping hot data in the cache, preventing cold queries from evicting important data. To avoid cache pollution, StarRocks excludes non-query activities like imports, materialized view refreshes, ETL tasks, and large scans from being cached.
-
Adaptive Cache Management StarRocks automatically manages the cache, adjusting its size dynamically based on available disk capacity. This ensures efficient resource use, freeing up space when needed for tasks like imports and ETL. Additionally, when disk throughput is low, StarRocks can bypass the cache and read directly from remote storage, maintaining optimal performance under varying conditions.
Case Study: Real-World Examples of StarRocks’ Caching
The effectiveness of StarRocks’ caching strategy is evident in real-world use cases, demonstrating substantial performance improvements.
A global travel company improves performance by 3.36x
One example comes from a global travel company that runs a Hive-based reporting platform integrated with BI tools like Superset. Many of their queries shared common elements, making them ideal candidates for caching. By leveraging StarRocks’ data caching capabilities, the company achieved a 3.36x performance boost, significantly speeding up its reporting processes.
A leading online shopping platform transitions from Presto to StarRocks
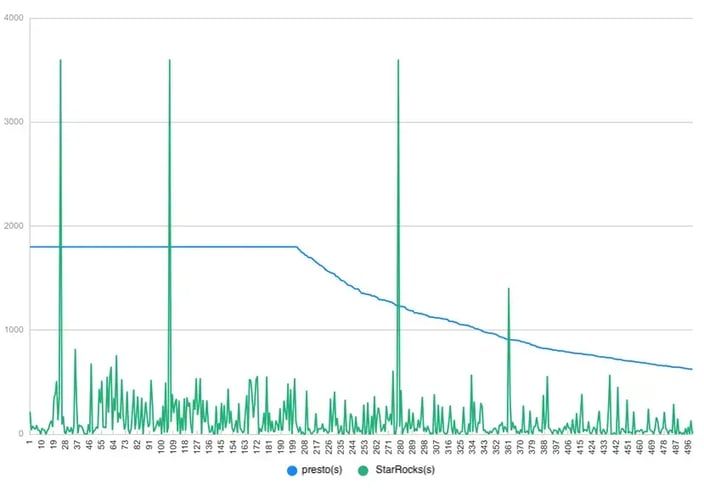
In another case, a leading online shopping platform compared the performance of a large Presto cluster against StarRocks. They tested the 500 longest-running queries from a Presto cluster of over 100 physical machines, where around 210 queries timed out after 1800 seconds (as indicated by the blue line in the graph).
In contrast, they ran the same queries on a StarRocks cluster with just 19 Xeon E5-2683V4 64C machines. Despite some network bottlenecks, StarRocks consistently delivered faster query performance, highlighting the importance of data localization for improving speed in high-demand environments.
Enable Customer-Facing Analytics on Lakehouse
Caching is key to enabling high-performance, customer-facing analytics on open lakehouse architectures. With the right strategy, it addresses critical challenges like data consistency, resource optimization, and inconsistent query performance. StarRocks demonstrates how an efficient caching solution can drastically improve query performance, even in high-demand environments.
To learn more about how to enhance your customer-facing analytics, join the conversation on StarRocks Slack.
